声明
本文是基于一篇英文文章翻译过来的。
原文链接:http://mrjoes.github.io/2013/06/21/python-realtime.html
原作者: Serge Koval
License:Creative Commons attribution-noncommercial-sharealike License
简介
最近我参与了 Flask book 的一次聚会,涉及到些realtime相关的问题-它是如何工作的, 如何整合实时部分与传统的WSGI应用,如何组织应用程序代码等。
我们使用Google Hangouts,原本打算将我们的Hangouts视频录下来,但失败了。 所以,我决定还是写一篇详尽的博客文章,其中包括一些基础知识,以及简短的介绍用Python异步编程等。
一点理论知识
让我们尝试解决服务器"推送"的问题。web都是拉取数据 - 浏览器发出请求到服务器,服务器会产生并发送回响应。 但是,如果有需要将数据主动从服务器推送到浏览器该怎么办呢?
解决方法很简单:浏览器发出AJAX请求到服务器,并要求更新。 虽然看起来这个是常用浏览器和服务器之间推送办法,但有一个问题:
如果服务器没有什么要发送,它会保持连接打开,直到为客户提供一些数据。 客户端收到响应后,它会发出另一个请求,以获得更多的数据。
这种技术被称为长轮询(long-polling)。
显然,这方法不不太高效。在大多数情况下,噪信比是非常高的 (无用数据比有用数据-因为这样一来更多的时间是花在处理HTTP请求(比如解析和验证报头)而不是实际数据发送到客户端。
但是,不幸的是,它是目前将数据推送到客户端最适合的方式。
基于HTTP/1.1情况好转了一点。TCP连接可以使用 Keep-Alive 头,默认情况下,连接在请求发起后将保持打开状态。 此功能使长轮询延迟得到了降低,这样就没有必要为每个轮询请求重新打开TCP连接。
HTTP/1.1还引入了 块传输协议 。 它允许讲响应分解为成更小的数据块,并将它们立即发送到客户端,而不是一直等到完成HTTP请求。
不幸的是,有些不兼容这个功能的代理服务器还是试图在转发之前缓存整个响应, 所以客户端将不会收到任何数据,直到代理认为HTTP请求已经完成。 虽然看起来web还是能"正常"工作 - 因为客户端最终还是会得到来自服务器的响应, 但它打破了为实时而设计的块传输协议的整体思路。
Opera在2006年9月,为它的浏览器实现了实验性的 服务事件发送 功能。 虽然SSE和块传输协议很相似,但还是是不同的协议,而且有更好的客户端API。
2009年4月23日,SSE得到WHATWG批准,得到几乎所有的现代的桌面浏览器(Internet Explorer的除外)的支持。 在这个链接你可以 看到兼容性图表 。
还有其他的技术,比如 forever-iframe 。 这是两种可以为Internet Explorer版本低于8做跨域推送的技术之一(另一个是 jsonp -polling),以及 HTMLFILE 等
总之,所有这些基于HTTP的折中方案都可以叫做 Comet 。
让我们来看看这些方法的利弊:
- 长轮询(Long-polling)是昂贵的,但兼容性很好。
- 块传输协议效率更高,但有可能不是所有客户端都能正常工作,并且如果没有某种形式的探测你都无法发现这个问题的存在。
- SSE也不错,但不是所有的浏览器都支持。比较好的是有办法在建立连接前就知道它是否支持。
但是,所有这些方法都有一个问题: 他们都只提供一种方式将数据从服务器推送到客户端,而不是在建立双向通信, 客户端每次想发送一些数据的时候,将不得不使用AJAX请求到服务器。 这样会增加延迟,并在服务器也会产生额外的负载。
邂逅WebSockets
虽然WebSockets的不是什么新技术,但经历了几个不兼容的迭代后该规范终于通过了,RFC编号:RFC-6455 。
简而言之,基于WebSocket的服务器和客户端之间建立的是基于TCP的双向连接。 连接的建立建立使用兼容HTTP的握手协议(加上额外的WebSocket相关的头),并具有额外的协议层次划分, 所以它也不仅仅是一个从浏览器中打开原始的TCP连接。
WebSocket协议最大的问题是浏览器支持,防火墙,代理服务器和防病毒应用的支持。
这个链接有浏览器的 兼容性图表 。
企业防火墙和代理服务器通常因各种原因阻止的WebSocket连接。
有些代理服务器不能处理WebSocket在端口80上连接 - 他们认为这是一般的HTTP请求,并尝试缓存它。 有HTTP扫描组件的杀毒软件也不允许WebSocket连接。
无论如何,WebSocket的来建立客户端和服务器端之间的双向通信是最好的方式,但不能单一的用来解决推送问题。
用例
鉴于以上情况,如果您的应用程序大多是从服务器推送数据,基于HTTP的传输会工作得很好。
但是,如果浏览器支持WebSocket的传输并且WebSocket的连接是可以建立的,它将是更好的选择。
总而言之,最好的办法是:尝试打开的WebSocket连接,如果失败 - 尝试回退到基于HTTP传输。 当然也有可以"升级"连接 - 首先使用长轮询(long-polling),然后尝试建立WebSocket的连接。 如果成功,就切换到WebSocket的连接。 虽然这种做法可能会降低初始连接的时间,需要注意服务器端实现, 以避免但在两者连接之间切换时发生任何的跳变情况(race conditions)。
Polyfill库
幸运的是,你没有必要自己实现这一切。 为所有已知的浏览器提供变通方案,搞定代理和防火墙的奇怪问题,尤其是从头开始搞这些事情,是非常困难的。 已经有人投入人多年的工作使他们的解决方案尽可能稳定。
有一些 polyfill 库,像 SockJS库 ,Socket.IO库 , Faye 和其他一些框架,实现了基于各种不同的传输实现上的类WebSocket的 API。
虽然他们所提供的服务器和客户端API不尽相同,但他们有着共同的理念: 在给定的情况下用最好的传输方案,并且提供一致的服务器端API。
例如,如果浏览器支持WebSocket协议,polyfill将尝试建立WebSocket连接。 如果失败了,他们将下降回到下一个最好的传输协议。 Engine.IO 使用稍微不同的方法 - 他先建立长轮询连接(long-polling),并尝试在后台升级到WebSocket。
在任何情况下 - 这些库将尝试建立双向连接到服务器上使用最可靠的传输。
不幸的是,在使用Socket.IO 0.8.x的时候有较差的体验。 我一般在我自己的项目中使用 sockjs-tornado ,即使我自己写了 TornadIO2 。 Socket.IO早期的server实现是基于 Tornado 的。
服务器端
让我们回到Python。
不幸的是,基于 WSGI 服务器不能被用于创建实时应用,因为WSGI协议是同步的。 WSGI服务器一次只能处理一个请求。
让我们再次回顾长轮询(long-polling)传输:
- 客户端打开HTTP连接到服务器,以获得更多的数据
- 无可用数据,服务器保持连接打开并等待数据发送
- 因为服务器无法处理任何其他请求,一切都被阻塞
用伪代码,它会看起来像这样:
def handle_request(request):
data = get_more_data(request)
return send_response(data)
如果get_more_data阻塞了,那整个服务器就会被阻塞,不能处理请求了。
当然,可以每个请求创建线程,但这非常低效。
虽然有一些变通办法(如 Armin Ronacher 所描述的方法,以及一些相关的变种将在稍后讨论,异步执行模式更适合这个任务。
在异步执行模式中,服务器处理依然在一个线程中顺序处理请求,但当处理程序无事可做的时候, 可以将控制转移到另一个请求处理程序。
在这种情况下,长轮询(long-polling)传输将看起来像这样:
- 客户端打开HTTP连接到服务器,以获得更多的数据
- 没有可用数据,服务器保持打开TCP连接,并同时做别的东西
- 当有数据要发送时,服务器发送数据然后关闭连接
Greenlets
在Python中有两种方法编写异步代码:
简而言之,greenlets让你写出能在执行过程中暂停的功能,然后还可以继续执行。
Greenlet的实现是从 Stackless Python 向后移植到CPython就。 虽然有greenlet模块的CPython看起来和Stackless Python是相同的 - 但他确实不是。 Stackless Python有两种上下文切换模式:软切换,硬切换。 软切换涉及到Python应用程序堆栈的切换(就是指针互换,快速并且容易)和硬切换需要堆栈分片(慢而且容易出错)。 Greenlet 基本上就是移植Stackless的硬切换模式。
让我们再次看看长轮询(long-polling)的例子,这次基于greenlets:
1, 客户端打开HTTP连接到服务器,以获得更多的数据 2, 服务器启动新的greenlet用来处理长轮询逻辑 3, 没有数据要发送,greenlet开始休眠,暂停当前正在执行的功能 4, 当有数据要发生的时候,greenlet唤醒,发送数据然后关闭连接
用伪代码,它看起来和同步版本完全一样:
def handle_request(request):
# 如果这里没有数据, greenlet 就会休眠
# 然后切换到其他greenlet执行
data = get_more_data(request)
return make_response(data)
为什么greenlets很重要?
因为它们允许以同步的方式编写异步代码。 他们允许异步的使用现有的同步库。greenlet的实现隐藏了上下文切换的问题。
GEVENT 是可以用greenlets实现的很好的例子。 这个框架补充了Python标准库,引入了异步IO(输入输出),在没有明显的上下文切换下使得所有代码异步。
另一方面,greenlet的 CPython实现也是相当可怕的。
每个协程都有自己的堆栈。CPython使用非托管堆栈的Python应用, 当Python程序运行时堆栈看起来像烤宽面条 - 解释器数据,本地模块的数据,Python应用程序的数据, 一切以随机顺序分层混合在一起。 在这种情况下,想要预留堆栈并且想无痛的做协同程序之间的上下文切换是相当困难的,因为很难预测在栈上保存的到底什么。
Greenlet试图通过把一部分栈数据复制到堆,然后复制回来的方法克服这一限制。 虽然大多数情况下它是可以工作的,但任何未经测试的第三方库与原生扩展,都有可能会产生奇怪的错误,如栈或堆破坏。
基于greenlets的代码实现方式也不太像线程。 因为他更容易造成死锁,代码实现中调用者其实并不希望调用的函数去暂停greenlet,但是这个函数却把greenlet暂停了,调用者将没有机会释放锁。
回调
做上下文切换的另一种方法是使用回调。以长轮询(long-polling)为例:
1, 客户端打开HTTP连接到服务器,以获得更多的数据 2, 服务器发现有没有数据发送 3, 服务器等待数据,并传入当有数据的时候应该被调用的callback函数 4, 服务器发送响应的回调函数,并关闭连接
在伪代码:
def handle_request(request):
get_more_data(request, callback=on_data)
def on_data(request):
send_response(request, make_response(data))
正如你看到的,工作流是相似的,但代码结构有所不同。
不幸的是,回调不是很直观,而且调试基于回调的大型应用程序简直就是个噩梦。 此外,这种方式很难让现有的"阻塞"类库与异步应用一起使用,除非做一些重写或使用某种形式的线程池。 例如, Motor ,为Tornado用混合方式实现的异步MongoDB的驱动程序-它用greenlets封装了 IO,但提供了与Tornado兼容的异步API。
Futures
有不同的方法来完善使用回调的情况:
- 使用futures
- 使用generators
什么是Futures?首先,Futures是一个函数的返回值,它是一个对象,它有以下几个属性:
1, 函数执行的状态(idling, running,停止等) 2, 返回值(如果函数尚未执行,可能是空的) 3, 各种方法: cancel(),以防止执行,add_done_callback方法,当绑定函数执行完毕时注册回调函数等。
您可以看看这篇优秀的 博客文章 ,其中比较了promises和回调,以及为什么对于写更好的异步代码来说promises优于纯写回调。
Generators
Python生成器也可让写异步程序的程序员更快乐一点。 我们还是看长轮询的例子,但这次我们基于生成器(请注意,从Python 3.3开始会允许从生成器返回值):
@coroutine
def handle_request(request):
data = yield get_more_data(request)
return make_response(data)
正如你可以看到,生成器允许编写的异步代码有点像同步方式。查看 PEP 342 获取的更多信息。
生成器最大的问题:程序员在还没有调用这个函数之前必须要知道他是否是异步函数。
看下面的例子:
@coroutine
def get_mode_data(request):
data = yield make_db_query(request.user_id)
return data
def process_request(request):
data = get_more_data(request)
return data
这行代码不会得到预期的效果,在python调用生成器函数返回的生成器器对象不包含执行的内容。 在这种情况下,process_request也应该变为为异步用coroutine装饰器封装并且应该从get_more_data产生。 另一种方法 - 使用框架功能运行异步函数(如通过回调或Future回调)的能力。
另一个问题 - 如果有必要使现有的函数异步,它的所有的调用者都应更新。
总结
Greenlets使一切变得"容易",但其代价是你可能遇到问题,并要允许隐式上下文切换。
使用回调的代码非常的乱。Futures使得情况有所改善。生成器使代码更易于阅读。
使用Python编写异步应用程序,似乎"官方"推荐的方式是使用回调/Futures/生成器,而不是greenlets。请参阅 PEP 3156 。
当然,没有什么会阻止您使用greenlet框架。有选择是件好事。
我更喜欢明确的上下文切换,因为在花了几个晚上生产环境中使用gdb搞清楚奇怪的解释器崩溃问题后,我对greenlets变得比较谨慎了。
异步框架
在大多数的情况下,完全没有必要写自己的异步网络层,应该更好地利用现有的框架。 在这里我就不一一列举所有的Python异步框架,我只说工作中使用的一个,所以不会对其他框架有所冒犯。
1, GEVENT不错,使编写异步程序变得容易,但就像上面说的,我不太适应greenlets。
2, Twisted是最古老的异步框架,即使是现在也有积极维护,。我个人的感受相当复杂:复杂,非PEP8,不容易学习。
3, Tornado是的我最终选择的框架。有几个原因:
- 快
- 可预测的
- 更符合Python的风格
- 相对较小
- 开发活跃
- 源代码很容易阅读和理解
Tornado没有Twisted大,并且没有一些同步调用库的异步移植(主要是DB方面), 但附带了Twisted reactor,所以它是可以在Tornado的基础上使用为Twisted编写的模块。
我会基于Tornado来解释后面所有的例子,但我敢肯定,类似的抽象同样可以用于其他框架。
Tornado
Tornado的结构是非常简单的。有一个主循环(称为IOLoop)。IOLoop检查socket, 文件描述符等的IO事件(借助 epoll, kqueue或select ),并管理基于时间的回调函数。 当有IO事件发生,Tornado调用注册的回调函数。
例如,如果绑定在某个socket上的的连接进来,Tornado将触发相应的回调函数, 这将创建HTTP请求处理程序类,然后从socket读取头部信息。
Tornado不仅只是epoll的一个封装 - 它包含自己的模板和认证系统,异步Web客户端等。
如果你不熟悉Tornado,看看这个相对较短的 框架概述 。
Tornado自带的WebSocket协议的实现,我也在这个基础上写了 sockjs 和 socket.io 库。
就像这篇文章开始的时候提到的,SockJS是WebSocket的polyfill库,在客户端是WebSocket对象, 在服务器端用socketjs-tornado提供类似的api。
SockJS负责选择客户端和服务器之间最佳的可用的传输方式,并建立逻辑连接。
这里是基于sockjs-tornado的简单聊天例子:
class ChatConnection(sockjs.tornado.SockJSConnection):
participants = set()
def on_open(self, info):
self.broadcast(self.participants, "Someone joined.")
self.participants.add(self)
def on_message(self, message):
self.broadcast(self.participants, message)
def on_close(self):
self.participants.remove(self)
self.broadcast(self.participants, "Someone left.")
为了举例,聊天不会有任何的内部协议或认证 - 它只是广播消息发送给所有的参与者。
没错,就这么就可以了。 如果客户端不支持WebSocket的传输,这不要紧,SockJS会回退去使用长轮询传输 - 开发人员只编写一次代码,sockjs-tornado负责抽象协议的差异。
逻辑是非常简单的:
对于每个传入SockJS连接,sockjs-tornado将创建新的连接类的实例,并调用on_open 在on_open中,处理程序将所广播有人有聊天者加入,并把聊天者的self加入参与者集合。 如果从客户端接收到一些消息,ON_MESSAGE将被调用并且消息将被广播给所有参与者 如果客户端断开连接,on_close将其从参与者集合中删除,并广播给剩下的所有参与者他离开了。
客户端的完整的例子可以在 这里找到 。
管理状态
服务器端的session是状态的一个例子。如果服务器需要某种先行数据才能处理请求,那服务器是状态相关的。
状态增加了复杂性 - 它消耗内存,它使伸缩更加困难。 例如,如果没有共享的session状态,客户只能和集群中的一台服务器"说话"。 共享会话状态 - 在为每一个请求从存储中获取状态的时候,每一次数据交换会有额外的IO开销。
不幸的是,无状态的Comet服务器是不可能实现。为了保持逻辑连接,需要一些会话状态来确保数据在客户端之间数据不会丢失。
根据任务,可以将有状态的网络层(Comet)和无状态的业务层(实际应用)分离开来。 在这种情况下,业务层完全不需要异步 - 接收到的任务,对其进行处理,并发送回响应。 因为worker是无状态的,就可以并行地启动大量的workers来增加应用程序整体的吞吐量的。
下面看他是如何工作的,架构图:
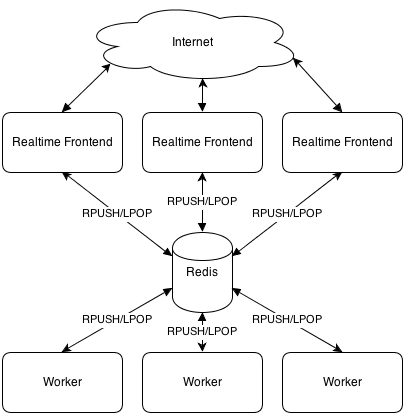
在这个例子中,使用Redis做同步传输,但是这会有单点故障,从可靠性角度来看不是太好。 此外,Redis的队列被用来向workers推送请求,并接收他们的响应。
由于网络层是有状态的,运行在应用程序前面负载均衡程序为了满足实时连接将使用粘性sessions(客户端应该每次去到相同的服务器)。
与WSGI应用集成
显然,使用新的异步框架重写现有的Web站点是不太可行的。但是可以让他们共存。
有两种方法来整合实时部分:
1, 在同一进程 2, 不在同一进程
如果使用GEVENT,它是可以使WSGI应用与实时部分共存于相同的进程。 如果使用tornado和其他基于回调的框架,尽管实时部分有可能运行在相同的进程中单独的线程,但是不被推荐这样做, 这有性能方面的问题(由于GIL )。
另外,我更喜欢独立进程的方法,其中单独设置进程/服务负责实时部分。 他们可能共存在一个项目/代码库,但他们总是同时但是单独进程运行的。
让我们假设你有一个社交网络,并希望实时推动状态更新。
最直接的方式来完成这个事情将是:建立单独的服务器来处理实时连接和监听从主站应用发来通知。
通知的实现可以通过实时服务提供的定制的REST API(适用于小型部署), 通过Redis的发布/订阅功能(很有可能你的项目已经使用Redis的东西了), 以及在ZeroMQ的帮助下,使用AMQP的消息总线(如RabbitMQ )等。
在这篇文章中我们将分析简单的推送broker架构。
组织你的代码
我会用Flask作为一个例子,但同样可以应用到任何其他的框架(Django,Pyramid等)。
我更喜欢一个代码仓库包含Flask应用和基于Tornado的实时部分。 在这种情况下,可以在这两个项目之间复用一些代码。
对于Flask,我使用普通的Python库:SQLAlchem??y,redis-PY等,对应Tornado, 我必须使用异步的替代库或者使用线程池来执行长时间运行的同步函数,以防止阻塞ioloop。
我manage.py有两个命令:启动Web应用程序和启动基于tornado的实时部分。
让我们看看一些用例。
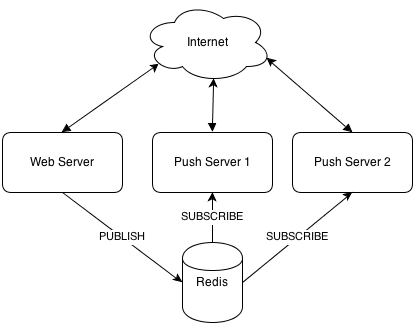
推送broker
Broker接受从Flask应用发来的消息,并将其转发到已连接的客户端。 有很多现成可以使用的broker服务( PubNub , Pusher及一些其他的或自托管解决方案,如Hookbox ), 但由于某种原因你可能要搭建自己的。
这最简单的推送broker:
class BrokerConnection(sockjs.tornado.SockJSConnection):
participants = set()
def on_open(self, info):
self.participants.add(self)
def on_message(self, message):
pass
def on_close(self):
self.participants.remove(self)
@classmethod
def pubsub(cls, data):
msg_type, msg_chan, msg = data
if msg_type == 'message':
for c in cls.clients:
c.send(msg)
if __name__ == '__main__':
# .. initialize tornado
# .. connect to redis
# .. subscribe to key
rclient.subscribe(v.key, BrokerConnection.pubsub)
完整的 例子在这里 。
broker是无状态的 - 他们真的不存储任何特定于应用程序的状态, 这样你就可根据不断增加的负载启动你需要数量的broker,只要负载正确配置好了。
游戏
让我们为一个"典型"的纸牌游戏做个架构草案。
假设,有一桌子,一组玩家在玩同一个游戏。 桌子可能包含可见牌和桌面的信息。 每个玩家有其内部状态 - 手上牌的列表,以及一些身份验证数据。
此外,对于游戏,客户端应该比较智能点,因为有可能需要有基于原始连接的自定义协议的。 为了简单起见,我们将使用定制的基于JSON协议。
让我们弄清楚我们需要什么样的消息:
- 验证
- 错误处理
- 房间列表
- 加入的房间
- 摸牌
- 出牌
- 离开房间
认证消息是从客户端发送到服务器的第一条消息。例如,它可以像:
{"msg": "auth", "token": "[encrypted-token-in-base64]"}
有效载荷是加密过的令牌,由Flask应用所产生。 有一种方法来生成令牌:获得当前用户ID,用时间戳和一些使用共享密钥加密对称算法(如3DES或AES)随机添加一些东西。 Tornado可以解密令牌,提取出用户ID,然后从数据库进行查询得到任何有关用户的必要的信息。
房间列表可以类似表示为:
{"msg": "room_list", "rooms": [{"name": "room1"}, {"name": "room2"}]}
依此类推。
在服务器端,每个SockJS连接被封装在类的实例中,它是可以使用self存储任玩家相关数据。
Connection类看起来像这个样子(部分):
class GameConnection(SockJSConnection):
def on_open(self, info):
self.authenticated = False
def on_message(self, data):
msg = json.loads(data)
msg_type = msg['msg']
if not self.authenticated and msg_type != 'auth':
self.send_error('authentication required')
return
if msg_type == 'auth':
self.handle_auth(msg)
return
elif msg_type == 'join_room':
# ... other handlers
pass
def handle_auth(self, msg):
user_id = decrypt_token(msg['token'])
if user_id is None:
self.send_error('invalid token')
return
self.authenticated = True
self.send_room_list()
def send_error(self, text):
self.send(json.dumps({'msg': 'error', 'text': text}))
房间可以存储在一个字典里,其中key是房间ID,value是房间对象。
通过在客户端上实现不同的的消息处理程序和适当的业务逻辑,我们就可以让游戏工作,这作为一个练习留给读者。
游戏是有状态的 - 服务器必须跟踪在比赛中发生了什么。这也意味着它是有点难以伸缩。
在上面的例子中,一台服务器处理所有连接的玩家的所有游戏。 但是,如果我们希望有两台服务器并且让玩家分布于它们之间呢? 由于他们不知道对方的状态,连接到第一台服务器的玩家将不能和第二台服务器上的玩家游戏。
根据游戏规则的复杂性,它是可以使用全连接的拓扑结构 - 每一个服务器连接到每一个其他的服务器:
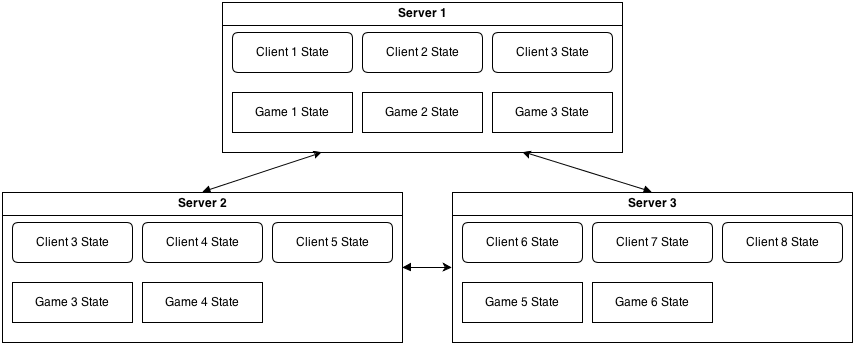
在这种情况下,游戏状态应该需要信息以确定玩家身份,管理他的游戏状态, 并且把游戏相关的信息发送到相应的服务器,这样状态就可以转发给实际客户端。
虽然这种方法有用,但异步应用程序是单线程的,更好的方式是将游戏逻辑和相关状态分离成单独的服务器应用程序, 把实时部分作为游戏服务器和客户端之间的智能适配器。
因此,它可以是这样的:
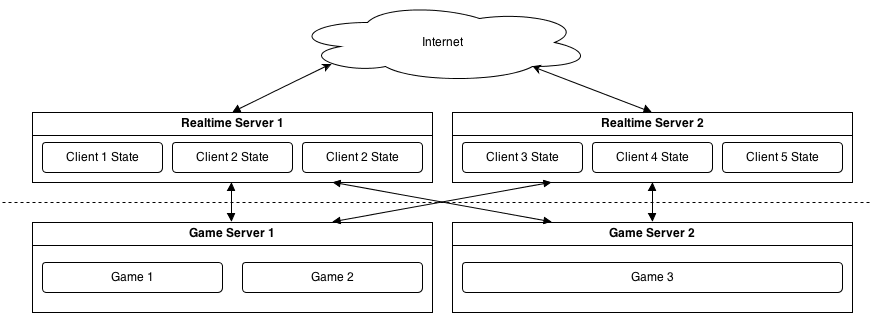
客户端连接到一个实时服务器,通过验证,获取正在运行的游戏列表(通过游戏服务器和实时服务器之间的一些共享状态)。 当客户端选择特定的游戏玩时,它会发送请求到实时服务器,然后在和真正部署该游戏服务器通信。 虽然这看起来和完全互连解决方案非常相似,但是在同一柜的服务器不需要与对方直接交互,这提供了有效的隔离状态。 伸缩也很简单 - 增加更多的的实时服务器或游戏服务器,由他们的状态是孤立的就易于管理。
另外,对于这个任务,我会使用ZeroMQ(AMQP总线)而不是Redis的,因为Redis会成为单点故障。
游戏服务器不会暴露在Internet中,他们只可以通过实时服务器访问。
我已经说过了,分布式应用程序的伸缩性就看 ** 状态管理是否高效 ** 。
部署
把Flask和Tornado放到负载均衡的后面(如haproxy ) 或反向代理服务器(即nginx 是个不错的想法,但要使用最新有WebSocket协议的支持的版本)。
有三种部署选项:
- 1, 把Web和实时部分都运行在相同的主机和端口,并使用基于URL路由分发
- 优点
- 所有的事情看起来是一致的
- 无需担心跨域脚本问题
- 一般可以工作在有防火墙限制的环境
- 缺点
- 一些透明HTTP代理服务器不兼容
- 2, 在相同主机的不同端口,Web在端口80上,实时部分在其他端口
- 优点
- 和透明代理更加兼容
- 缺点
- 跨域脚本问题(不是每个浏览器都支持CORS )
- 很有可能被防火墙阻止
- 3, Web运行在主要域(site.com)和实时部分运行在子域(subdomain.site.com)
- 优点
- 可以将实时部分从主站点分离出来(无需使用相同的负载均衡)
- 缺点
- 跨域脚本问题
- 会碰到行为古怪的透明代理
现实生活中的经验
我看到过一些使用sockjs-tornado的成功案例: PlayBuildy PythonAnywhere 和其他的。
但不幸的是,我自己没有在大型项目中使用过。
不过,我有相当有趣的sockjs-node(为nodejs做的SockJS的服务器实现)经验。 我实现了一个比较大的广播电台的实时部分。 在同一时间平均有3500左右连接的客户端。
大多数连接是短时的,服务器就仅仅是一个简单的broker: 管理有层次的频道订阅(例如广播站事件推送或广播员的新闻推送)和频道日志。 客户订阅频道,应该可以获得所有为子频道推送的更新。 客户也可以申请频道日志 - 按日期排序的最新N个频道和其子频道的消息。 这就是一部分在服务器上的逻辑。
总体而言,nodejs的表现是很不错的 - 在一台物理服务器上的3个服务器进程就能够毫无压力处理所有这些客户端的链接, 而且还有很多的提升空间。
但就我看来,nodejs和其库有太多的问题了。
部署到生产环境后,服务器开始没有明显原因的内存泄漏。 所有的工具表明,堆大小是恒定的,但服务器进程的RSS不断增长,直到进程被操作系统杀掉。 作为一个快速的解决方案,nodejs服务器必须每天晚上重新启动。 这个问题问题和这个这个比较相似,但这个SSL没有关系,因为没有使用SSL。
如果没有明显的原因的崩溃而且没有产生coredump,那么升级到较新的nodejs版本有帮助。
如果V8垃圾收集器开始在某些情况下死锁了而且是一天一次的频率发生。 那么升级到较新的nodejs版本会有帮助,它是发生在V8中的死锁,我在Chrominu的bug跟踪服务里面发现了完全相同的堆栈信息。
新的nodejs版本解决了垃圾收集的问题,应用又可以工作。
此外,基于回调的编程风格使得代码不是我希望中的那么干净和可读。
概括起来 - 尽管nodejs能工作,我有一种强烈的感觉是它没有Python那样成熟。 在以后这样的项目中我宁愿使用Python, 因为我可以肯定,如果出现错误,它发生了是因为我出了错,而且问题可以追溯到,这样就相对容易。
性能方面,使用WebSocket传输,CPython和nodejs 是差不多的而 PYPY比两者都快得多。 对于长轮询,PYPY环境的Tornado在使用适当的异步库的情况下,约1.5-2倍慢于nodejs,因此, 考虑目前的WebSocket兼容状态,我会说他们是可比的。
我没有理由放弃的Python而用nodejs来做实时部分。
更新(2013年7月2日): TechEmpower 发布了他们的 第6轮 的框架基准测试,新版本的Tornado更快了,或与node.js有的一比。
备注:
虽然有人可能会争辩说,要编写出可伸缩的服务器,Python并不是最好的语言。 当然, Erlang的已经有内建的工具来写高效和可扩展的应用程序(而且也有 sockjs-erlang ), 但是要找到erlang的开发人员是比较困难的。 Clojure和Scala也是不错的选项,但Java是完全不同的世界,有自己的类库,方法论和约定。 找到不错的Clojure开发者仍然比找到好的Python开发者很难很多。 Go 也不错,但他是相当年轻的语言接受程度还不高。
如果你已经有了Python的经验,你可以继续使用Python达到不错的结果。 在大多数情况下,软件开发就是开发成本和性能之间的一个权衡。 我认为Python所处的位置还比较有利,特别是借助于 PYPY 。
无论如何,如果你有任何意见,问题或更新 - 随时与我联系。
P.S. 图表是在 draw.io 上完成的 -我不得不提一下这个优秀且免费的服务。